Overall Summary
The requirements for Fall 2015 are viewable here.
We were able to get all the modules to the point where you can load data into the database schema we designed and the data will make its way to the browser. There are two things that are missing at this moment:
- The audio server is still a prototype, we did not get it to where it synthesizes audio from the database. As such: the page will not play the corresponding moment audio. However this module is 90% close to completion, so with little effort it can be made to play audio properly.
- The transcript functionality is implemented on the client side but not on the API server. This was mostly due to a lack of test data.
I will go into more detail below.
What got done
- Set up framework for collaboration and communication
- Gathered requirements
- Set up development infrastructure
- Set up application infrastructure
- First iteration of database schema
- First iteration of API server
- First iteration of Client application
- Audio composition/streaming server prototype
Work Summary
Framework for Collaboration
I set up a GitHub organization (https://github.com/utd-crss) and added everyone as collaborators. This way all of the source code is housed under one roof on a platform most people are familiar with. I also set up a Slack channel for day-to-day communication. For non-development related documentation such as meeting notes and presentations I set up a shared Google docs folder.
This setup can be used by the next team. They do not have to worry about setting up their own channels for communication and such.
Requirements Gathered and Documented
From our meetings we extracted:
- Requirements Document
- Application Design Wireframes
- Documentation on rationale behind tech decisions
Versioned documentation is available on GitHub:
Development Infrastructure
I set up extensive development infrastructure for all the modules involved. The development infrastructure is built with modern industry best-practises in mind. Another central win of the infrastructure we set up was as well as ease of onboarding new collaborators.
The setup includes:
- Git source control repositories
- Continuous integration
- Continuous deployment
- Unit testing
- Documentation on how to contribute to and run each of the projects
Project Repositories
- project.exploreapollo.org: Overall project planning and documentation.
- exploreapollo.org: The entry point for the exploreapollo.org project.
- audio.exploreapollo.org: Provides endpoints that mixes and streams combinations of audio channels.
- exploreapollo.org-schema: Documentation and scripts to support the RDBMS used by the API and audio servers.
- app.exploreapollo.org: The primary web application interface.
- API.exploreapollo.org: Provides REST and WebSocket endpoints for the web application.
Advantages of continuous integration and continuous deployment
If you do not know what continuous integration or continuous deployment are I encourage you to read up on them.
In short:
Continuous integration scrutinizes every single code commit to each of the projects and makes sure it meets standards and that the contribution does not break existing functionality. It does things like test to make sure the application runs in various different browsers without errors.
Continuous (automated) deployment means that all validated and tested contributions to the project are automatically rolled out to their respective servers. This means all the user-facing modules are always up-to-date and nobody has to worry about complicated manual deployment processes.
Unit Testing
All the projects have a unit testing framework setup with at least some sort of “smoke test”. Unit tests are run before each deploy to make sure the applications are functioning properly.
Project Documentation
Each project has a README document that allows anyone to run and or contribute to the code only by following the instructions. You can view an example here.
Application Infrastructure
I set up fully functioning production server environments for each project module. These servers are being deployed to continuously and are ready to go for public release when the time comes. You can read more about the application infrastructure here
- Databases created on AWS RDS
- Audio server hosted on Heroku
- API server hosted on Heroku
- Client application hosted on AWS S3 with AWS Cloudfront in front of it
- The audio data is stored on AWS S3
Database Schema
We were able to successfully create, deploy, and document a database schema that represents the data that flows through the application. This is deployed to production and ready to be loaded with real data.
View the project repo: exploreapollo.org-schema
API Server first iteration
We were able to successfully design, implement, and document all the necessary REST endpoints that the client needs to function. Transcript functionality is designed and implemented but impossible to test without good test data.
View the project repo: API.exploreapollo.org
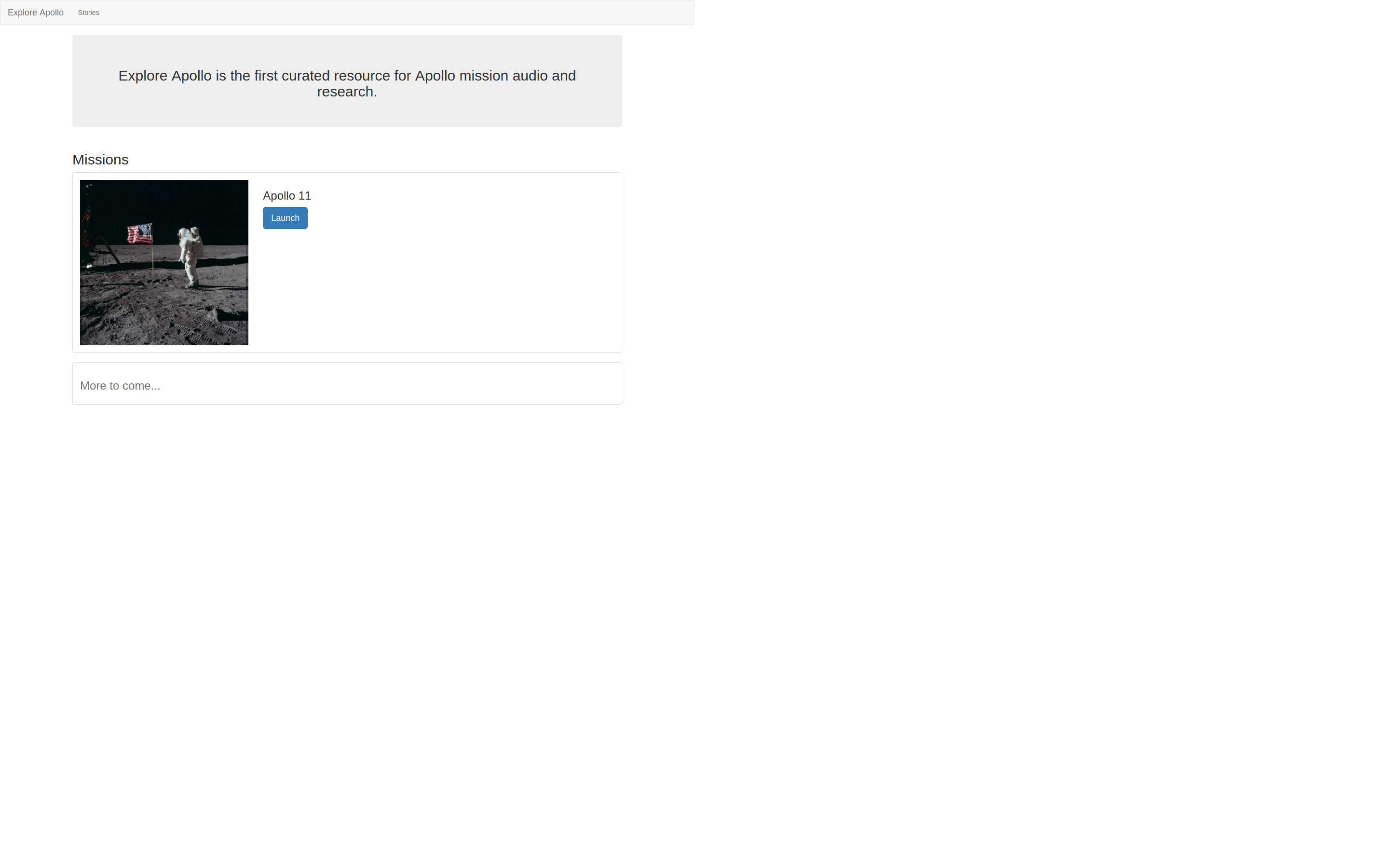
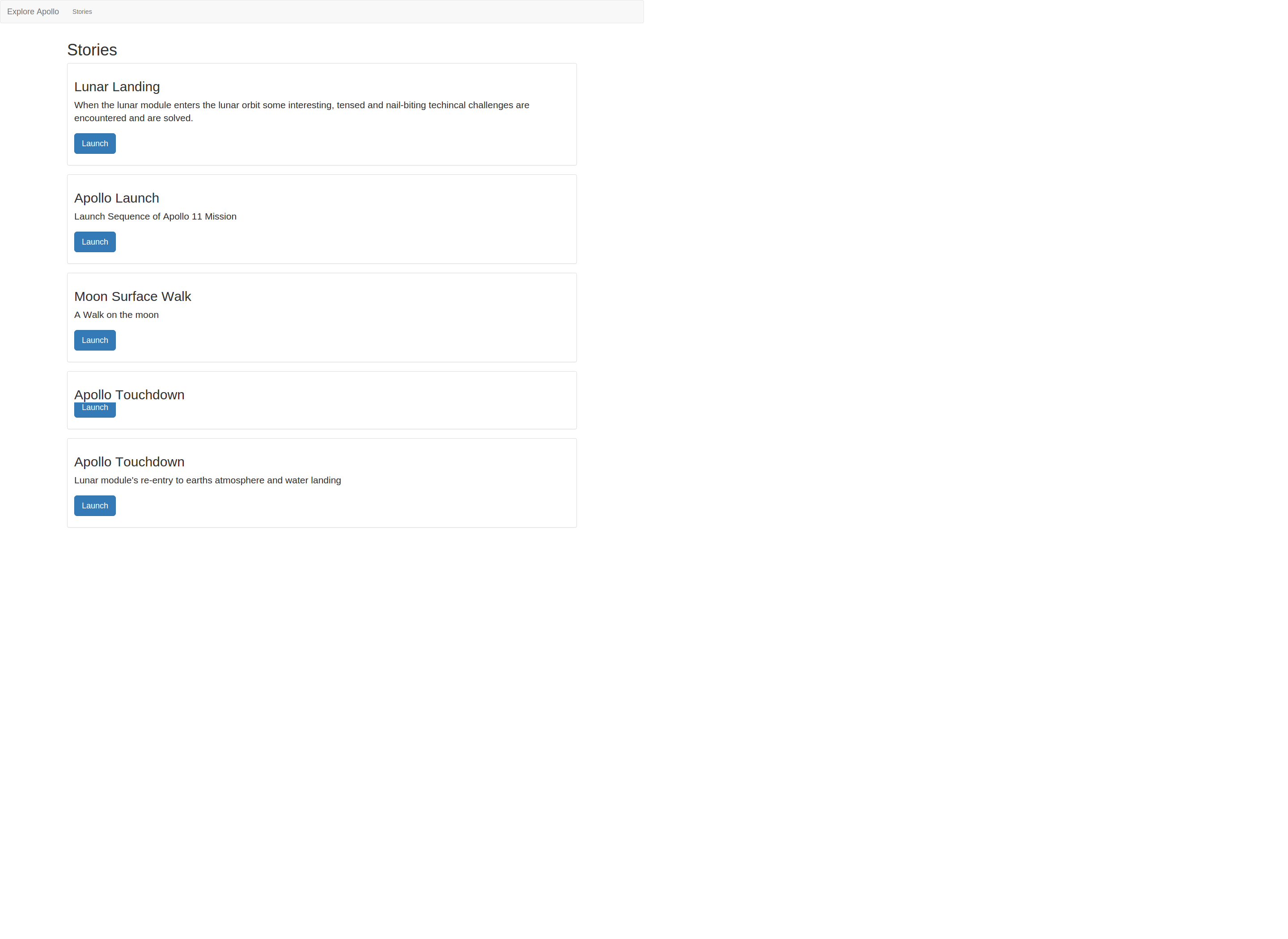
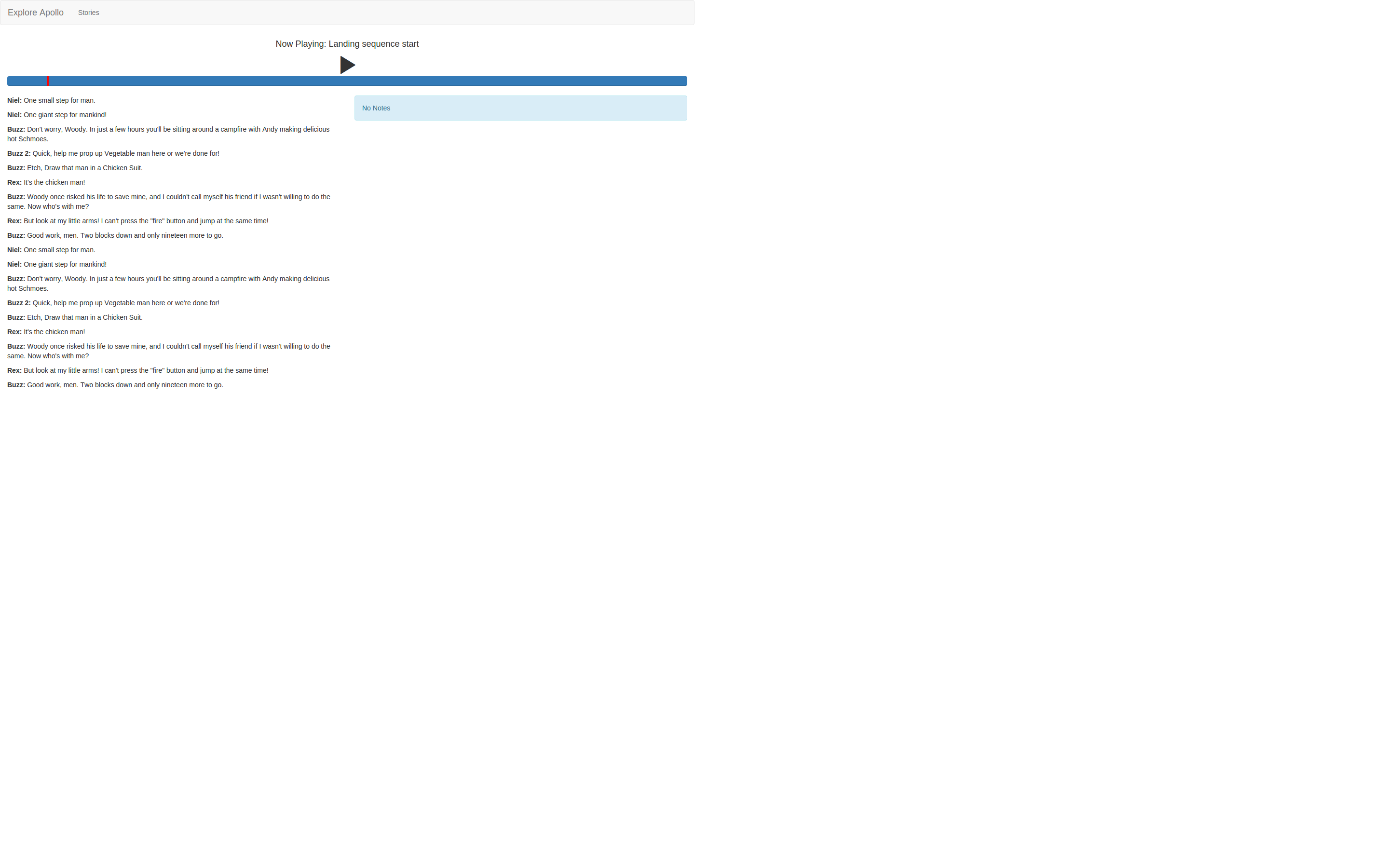
First Iteration of Client Application
We were able to implement all the basic user-facing views. The Client application talks to the API server successfully.
View the project repo: app.exploreapollo.org
Screenshots
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Audio Composition/Streaming Server Prototype
We are able to successfully take a variable number of channels, mash them up, and stream them to the user.
We have a bunch of code that attempts to implement the necessary database queries to make it stream audio based on client requests. This is yet to be reviewed or tested.
View the project repo: audio.exploreapollo.org
Recommendations for Future Teams
Weekly meetings should ONLY contain project update discussion
This is less of a problem now that the requirements are settled, but we wasted a lot of time having meetings where we basically just rehashed the existing requirements that everyone already understood.
The ONLY things that should be talked about at the weekly project update discussions should be:
- “I completed/did not complete X action item”
- “The next thing I am going to work on is X”
Perhaps we should even reduce the length of these meetings from an hour to 30 minutes.
Weekly “Office Hours” would be helpful
There is any value in “in-person” working meetings. However, there should be a couple hours per week where everyone logs into slack and is actively working on the project. That way people can ask each other questions and collaborate rather than wait for the weekly meetings to get questions answered.
If everyone had a minimal amount of scheduled hours to work on the project it would make work “mandatory”. One problem we had was team members not putting in the amount of hours needed to make sufficient progress.